Hardware Overview
Hardware Overview
ARIS is the name of the Greek supercomputer, deployed and operated by GRNET S.A. (National Infrastructures for Research and Technology S.A.) in Athens. ARIS consists of 532 computational nodes seperated in four “islands” as listed here:
- 426 thin nodes: Regular compute nodes without accelerator.
- 44 gpu nodes: “2 x NVIDIA Tesla k40m” accelerated nodes.
- 18 phi nodes: “2 x INTEL Xeon Phi 7120p” accelerated nodes.
- 44 fat nodes: Fat compute nodes have larger number of cores and memory per core than a thin node.
- 1 ml node: “8 x NVIDIA Volta V100” accelerators
All the nodes are connected via Infiniband network and share 2PB GPFS storage.
Access to the system is provided by two login nodes.
Nodes Summary
| Node Type |
Count |
Accelerator |
Memory |
Cores |
| THIN nodes |
426 |
w/o |
64 GB |
20@2.8 GHz (two sockets) |
| GPU nodes |
44 |
dual tesla k40m |
64 GB |
20@2.6 GHz + 2 x K40 |
| PHI nodes |
18 |
dual xeon phi 7120p |
64 GB |
20@2.6 GHz + 2 x 7120p |
| FAT nodes |
44 |
w/o |
512 GB |
40@2.4 GHz (four sockets) |
| ML node |
1 |
8 volta v100 |
512 GB |
40@2.2 GHz (two sockets) |
|
|
| Architecture |
x86-64 |
| Operating System |
Redhat/Centos 6.7 |
| Interconnect |
|
| Technology |
Infiniband FDR |
| Topology |
Fat tree |
| Bandwidth [Gb/s] |
56 |
| Storage |
|
| Type |
IBM GPFS |
| Size [PByte] |
1 |
| Bandwidth [GB/s] |
6 |
| System Software |
|
| Operating system |
RedHat/Centos Linux 6.7 |
| Batch system |
SLURM |
| System Management |
xCat IBM |
| Monitoring |
Nagios, Ganglia |
Technical Info
Thin nodes
The 426 thin compute nodes (thin node island) have a theoretical peak performance (Rpeak) of 190,85 TFlops and a sustained performance (Rmax) of 179,73 TFlops on the Linpack benchmark. The systems was ranked #468 in the Top500 list of most powerful systems in the world when it was installed (June 2015 iteration). The thin island is best suited for high-scalable applications utilizing MPI or hybrid MPI/OpenMP programming.
| THIN nodes technical information |
|
| Architecture |
x86-64 |
| System |
IBM NeXtScale nx360 M4 |
| Total number of nodes |
426 |
| Total number of cores |
8520 |
| Total amount of RAM [TByte] |
27 |
| Total Linpack Performance [TFlop/s] |
180 |
| Components |
|
| Processor Type |
Ivy Bridge - Intel Xeon E5-2680v2 |
| Nominal Frequency [GHz] |
2.8 |
| Processors per Node |
2 |
| Cores per Processor |
10 |
| Cores per Node |
20 |
| Hyperthreading |
OFF |
| Memory |
|
| Memory per Node [GByte] |
64 |
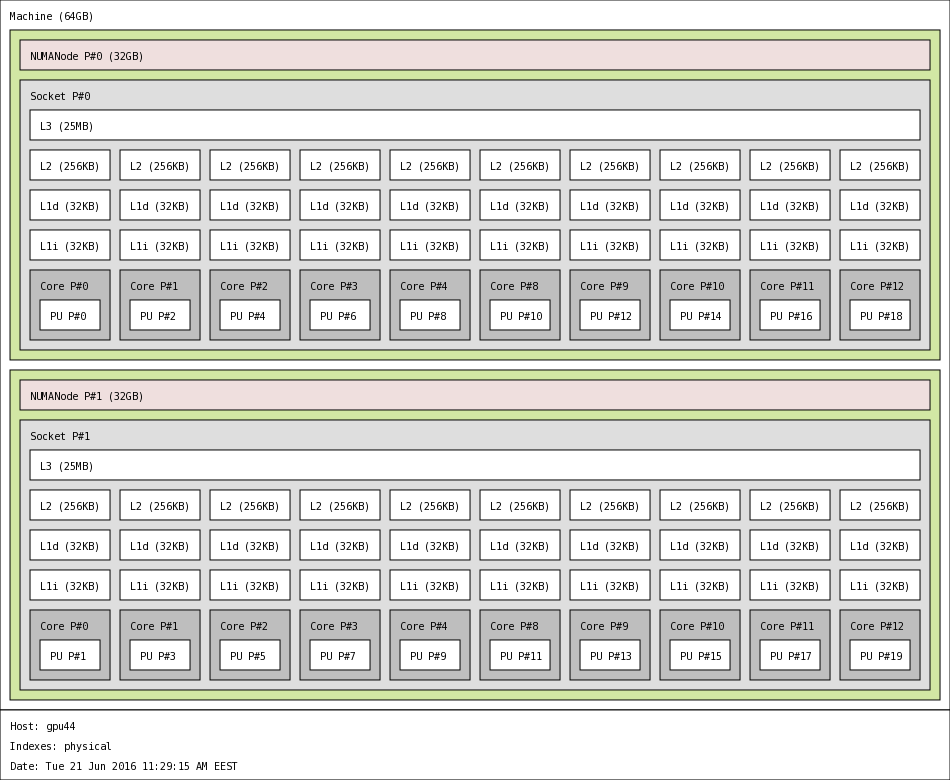
GPU nodes
44 GPU nodes offer a combined total theoritical peak performance of 162,45 TFlops (36,61 TFlops from CPUs and 125,84 TFlops from GPUs). Each NVidia K40 GPU incorporate 2880 CUDA cores.
| GPU nodes technical information |
|
| Architecture |
x86-64 |
| System |
DELL PowerEdge R730 |
| Total number of nodes |
44 |
| Total number of cores |
880 |
| Total number of gpus |
88 |
| Total amount of RAM [TByte] |
2,8 |
| Total Linpack Performance [TFlop/s] |
83,65 |
| Components |
|
| Processor Type |
Haswell - Intel(R) Xeon(R) E5-2660v3 |
| Nominal Frequency [GHz] |
2.6 |
| Processors per Node |
2 |
| Cores per Processor |
10 |
| Cores per Node |
20 |
| Hyperthreading |
OFF |
| Accelerators |
|
| Accelerator type |
GPU - NVIDIA Tesla K40 |
| Accelerators per node |
2 |
| Accelerator memory [GByte] |
12 |
| Memory |
|
| Memory per Node [GByte] |
64 |
PHI nodes
Phi nodes are so called because they include dual Intel Xeon Phi 7120P accelerators. They offer a combined theoritical peak performance of 58,46 TFlops (14,98 TFlops from CPUs and 43,49 from the accelerators). Phi nodes are appropriate for fast scaling of existing x86 codes. Vectorized codes will take advantage of the full potential of Intel MIC architecture.
| PHI nodes technical information |
|
| Architecture |
x86-64 |
| System |
DELL PowerEdge R730 |
| Total number of nodes |
18 |
| Total number of phi’s |
36 |
| Total number of cores |
360 |
| Total amount of RAM [TByte] |
1,1 |
| Total Linpack Performance [TFlop/s] |
39,04 |
| Components |
|
| Processor Type |
Haswell - Intel(R) Xeon(R) E5-2660v3 |
| Nominal Frequency [GHz] |
2.6 |
| Processors per Node |
2 |
| Cores per Processor |
10 |
| Cores per Node |
20 |
| Hyperthreading |
OFF |
| Accelerators |
|
| Accelerator type |
MIC - Intel Xeon Phi Coprocessor 7120P |
| Accelerators per node |
2 |
| Accelerator memory [GByte] |
16 |
| Memory |
|
| Memory per Node [GByte] |
64 |
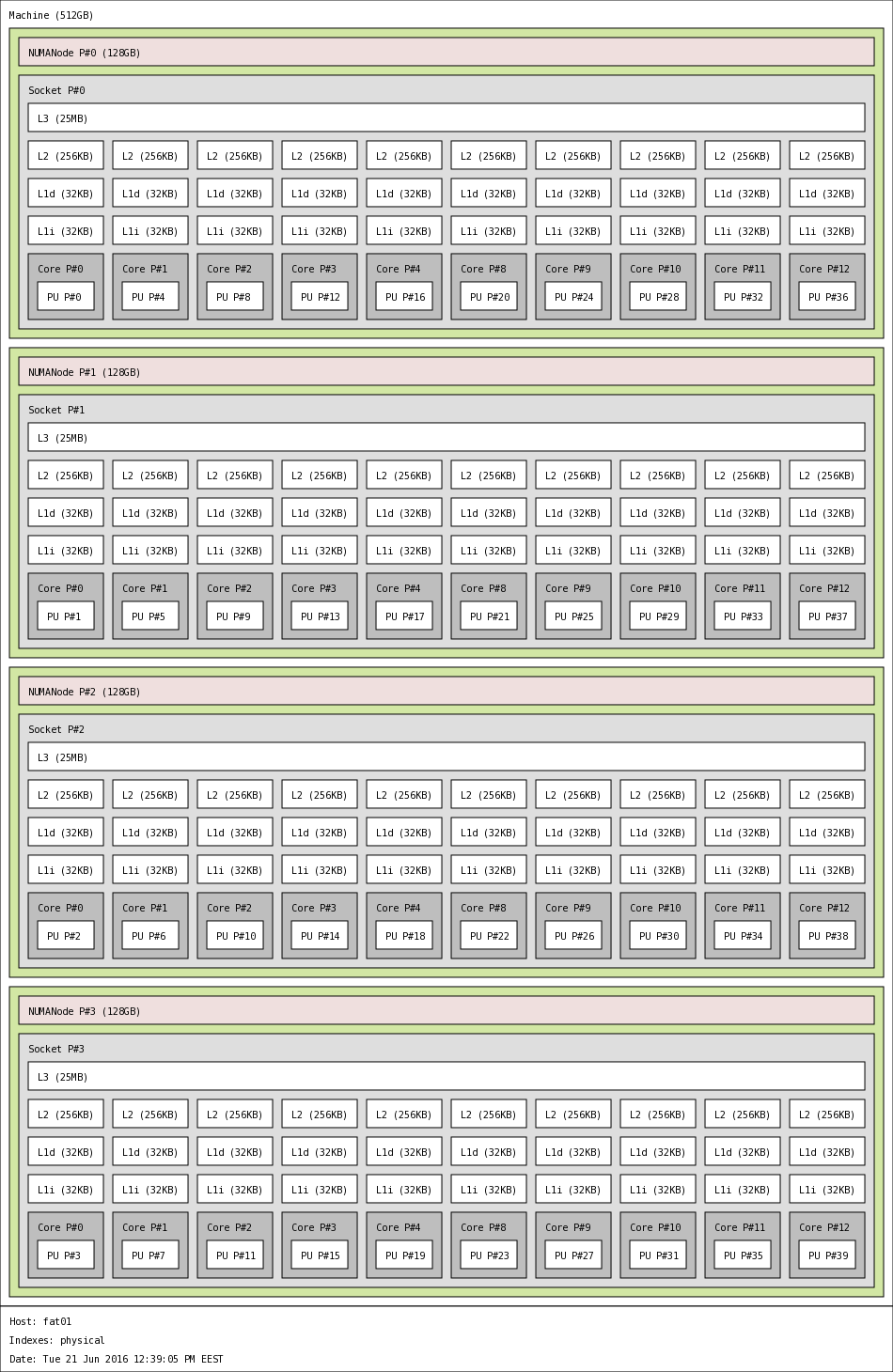
Fat nodes
Fat nodes offer more cores and more memory per server comparing with the regular two-socket nodes (thin, phi, gpu). The total theoritical performance is 33,79 TFlops. Fat nodes are best suited for shared memory applications (e.g. OpenMP-based) and in general applications that require to perform in-memory processing of large datasets.
| FAT nodes technical information |
|
| Architecture |
x86-64 |
| System |
DELL PowerEdge R820 |
| Total number of nodes |
44 |
| Total number of cores |
1760 |
| Total amount of RAM [TByte] |
22,5 |
| Total Linpack Performance [TFlop/s] |
32,01 |
| Components |
|
| Processor Type |
SandyBridge - Intel(R) Xeon(R) CPU E5-4650v2 |
| Nominal Frequency [GHz] |
2.4 |
| Processors per Node |
4 |
| Cores per Processor |
10 |
| Cores per Node |
40 |
| Hyperthreading |
OFF |
| Memory |
|
| Memory per Node [GByte] |
512 |
ML node
| ML node technical information |
|
| Architecture |
x86-64 |
| Total number of nodes |
1 |
| Total number of cores |
40 |
| Total number of threads |
80 |
| Total number of gpus |
8 |
| Total amount of RAM [GByte] |
512 |
| Components |
|
| Processor Type |
Broadwell - Intel(R) Xeon(R) E5-2698v4 |
| Nominal Frequency [GHz] |
2.2 |
| Processors per Node |
2 |
| Cores per Processor |
20 |
| Cores per Node |
40 |
| Threads per Node |
80 |
| Hyperthreading |
ON |
| Accelerators |
|
| Accelerator type |
GPU - NVIDIA Volta V100 |
| Accelerators per node |
8 |
| Accelerator memory [GByte] |
16 |
Login nodes
| Login nodes |
|
| Number of Nodes |
2 |
| Processor Type |
Intel(R) Xeon(R) CPU E5-2640 v2 |
| Nominal Frequency [GHz] |
2.00GHz |
| Processors per Node |
2 |
| Cores per Processor |
16 |
| Threads per Processor |
32 |
| Hyperthreading |
ON |
| Memory per Node [GByte] |
128 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}